
Automatic Temporized Rds Scaling
6 minutes reading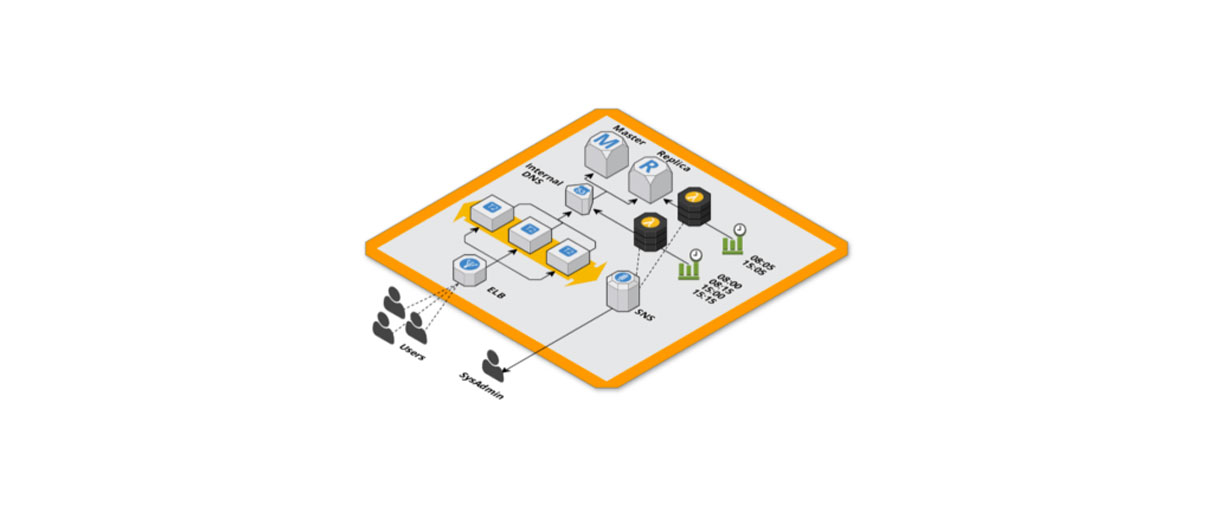
Temporized RDS read replica AutoScaling with Lambda and Route53
Starting situation
One of our hosting infrastructure on AWS recently has encountered some problems due to a huge and rapid increase in traffic during some pre-defined periods, at the same time as a newsletter, that quickly brought many more users to visit our customer’s Magento e-commerce.
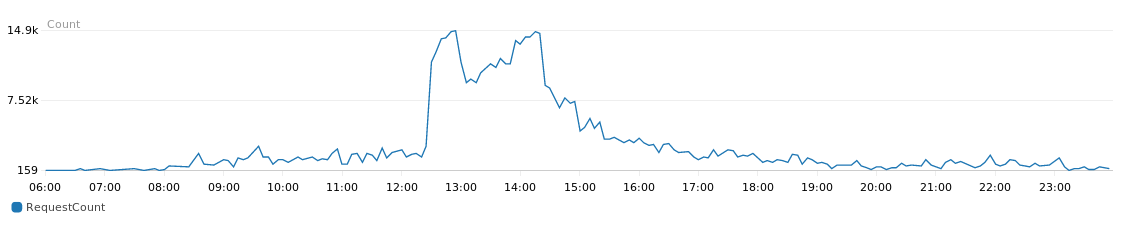
The number of requests made to our ElasticLoadBalancer ranged from 400 to 3,000 per minute in less than 5 minutes, that did not give us enough time to scale-up the infrastructure before it fall down. From our analysis we have identified the bottleneck in the database, especially in categories and catalog read queries, dynamics based on various configurations and based on the connected user.
RDS master and replica
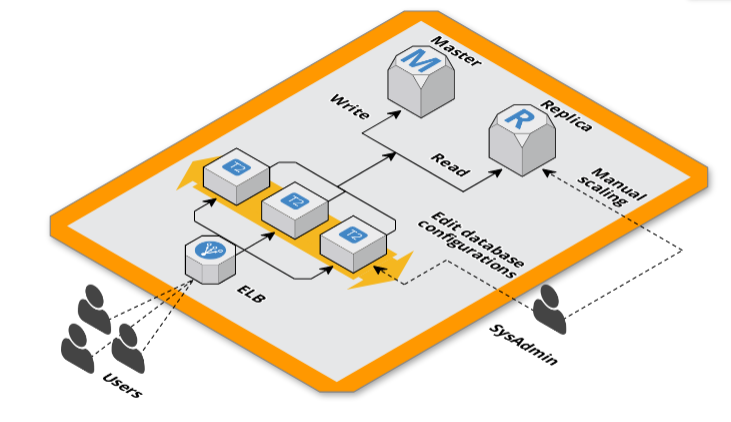
To better control the load on the database, we have decided to use two RDS instances, a master for write operations, and a replica for read operations to only scale the necessary part and control costs. We noticed an improvement but the same reading replication suffered from the load and they quickly saturated the database connections.
Scheduled Scaling
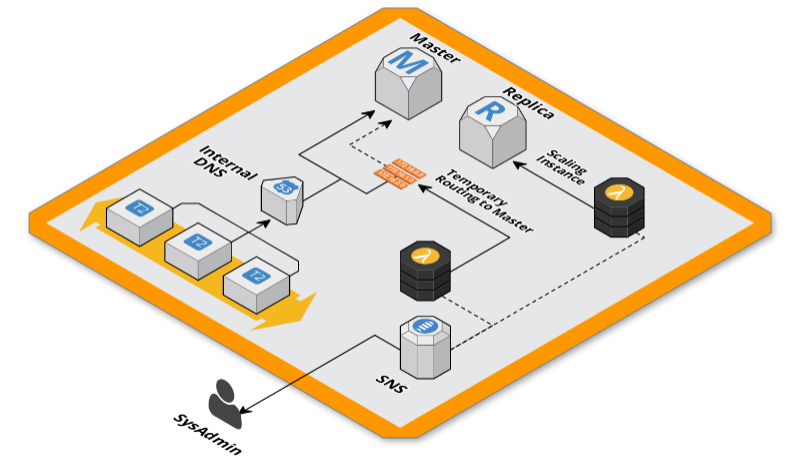
To prepare us for incoming traffic, one hour before the peak of traffic, we changed the database endpoint from the Magento configurations to not use the replication. When the scaling was done we brought the configuration back to the previous one.
This solution worked fine but it was very uncomfortable to change the Magento configurations, so we had to empty the cache and this would be a further burden on the first few site visits in addition to having to manually process the procedures with the risk of human error.
Internal DNS with Route53
The solution we adopted for not having to modify the connection configurations of the Magento database endpoint was to use internal VPC DNS managed with Route53 by mapping the hosts of RDS instances with domain names using CNAME records in the magento configurations file.
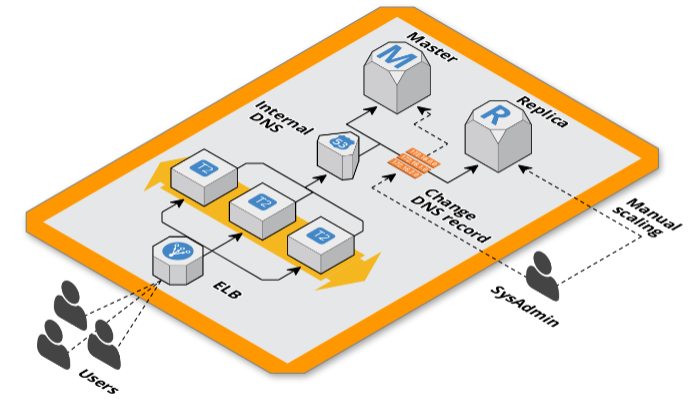
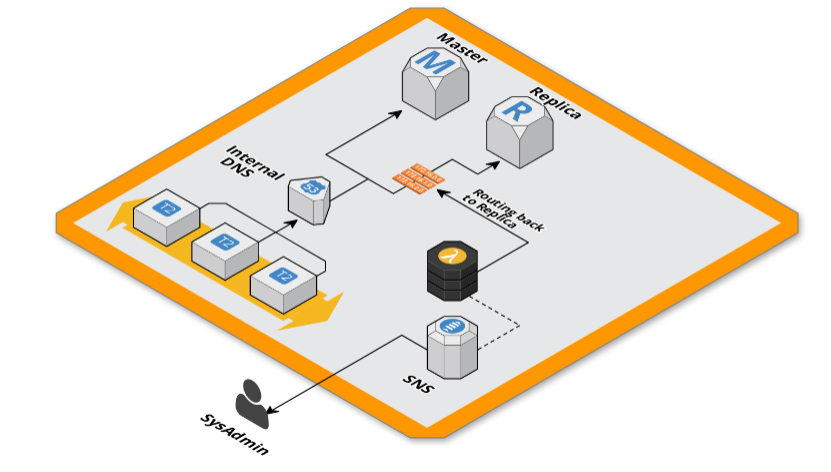
This way we have the control of pointing the web application to the database agnostically to its configurations. This allows us to redirect the read replication connections to the master during scaling and this not generate any downtime.
Computers will steal our job
Once we have reached a stable solution that allows us to scale without downtime, it only remains to set this procedure automatically.
“This is a task for Lambda,” we said, so we wrote two Lambda functions in NodeJS that are able to modify the RDS instance and the Route53 DNS record attached to its endpoint. For this small project we chose to use the Serverless framework that we used in the past with great satisfaction.
functions:
routingToMaster:
handler: route53.changeRecord
environment:
Msg: "${self:custom.MsgRoutingToMaster}"
HostedZoneId: "${self:custom.HostedZoneId}"
RecordName: "${self:custom.RecordName}"
RecordValue: "${self:custom.MasterEndpoint}"
scaleUp:
handler: rds.scale
environment:
Msg: "${self:custom.MsgScaleUp}"
InstanceIdentifier: "${self:custom.InstanceIdentifier}"
InstanceClass: "${self:custom.InstanceClassBig}"
scaleDown:
handler: rds.scale
environment:
Msg: "${self:custom.MsgScaleDown}"
InstanceIdentifier: "${self:custom.InstanceIdentifier}"
InstanceClass: "${self:custom.InstanceClassSmall}"
routingToReplica:
handler: route53.changeRecord
environment:
Msg: "${self:custom.MsgRoutingToReplica}"
HostedZoneId: "${self:custom.HostedZoneId}"
RecordName: "${self:custom.RecordName}"
RecordValue: "${self:custom.ReplicaEndpoint}"The Lambda functions are called with two different configurations for each, the first DNS to point to the master and then to re-point towards the replica
'use strict';
const AWS = require('aws-sdk');
const route53 = new AWS.Route53();
const sns = require('./lib/sns.js');
module.exports.changeRecord = (event, context, callback) => {
route53.changeResourceRecordSets({
ChangeBatch: {
Changes: [{
Action: 'UPSERT',
ResourceRecordSet: {
Name: process.env.RecordName,
Type: 'CNAME',
ResourceRecords: [{
Value: process.env.RecordValue
}],
TTL: 60
}
}],
Comment: "managed by lambda"
},
HostedZoneId: process.env.HostedZoneId
}, function(err, data){
if(err){
sns.error("Cannot change DNS record "+process.env.RecordName+" to value "+process.env.RecordValue, function(){
callback(err);
})
}else{
sns.notify(process.env.Msg, callback)
}
});
};
for RDS for a scale-up and a scale-down to the starting size.
'use strict';
const AWS = require('aws-sdk');
const rds = new AWS.RDS();
const sns = require('./lib/sns.js');
module.exports.scale = (event, context, callback) => {
rds.modifyDBInstance({
DBInstanceIdentifier: process.env.InstanceIdentifier,
DBInstanceClass: process.env.InstanceClass,
ApplyImmediately: true
}, function(err, data){
if(err){
sns.error("Cannot scale RDS instance "+process.env.InstanceIdentifier+" to "+process.env.InstanceClass, function(){
callback(err);
})
}else{
sns.notify(process.env.Msg, callback)
}
});
};
We’ve added message submissions to an SNS topic to be notified when the transactions took place and in case of problems be ready to intervene.
'use strict';
const AWS = require('aws-sdk');
const sns = new AWS.SNS();
module.exports.notify = (msg, callback) => {
sns.publish({
Message: msg,
TopicArn: process.env.NotificationSNS
}, callback);
};
module.exports.error = (error, callback) => {
sns.publish({
Message: process.env.MsgError +": "+ error,
TopicArn: process.env.NotificationSNS
}, callback);
};
We have a generic Lambda function attached on the topic capable of processing many types of incoming messages on a specific topic and forwarding them to a specific Slack Room.
Once the code was written, minimal and simple, and configured the Serverless project was enough to execute a single deploy command to have all the environment up&running.
You can find the entire code here: bitbull-team/aws-rds-autoscaling
Scheduled and Automatic Scale
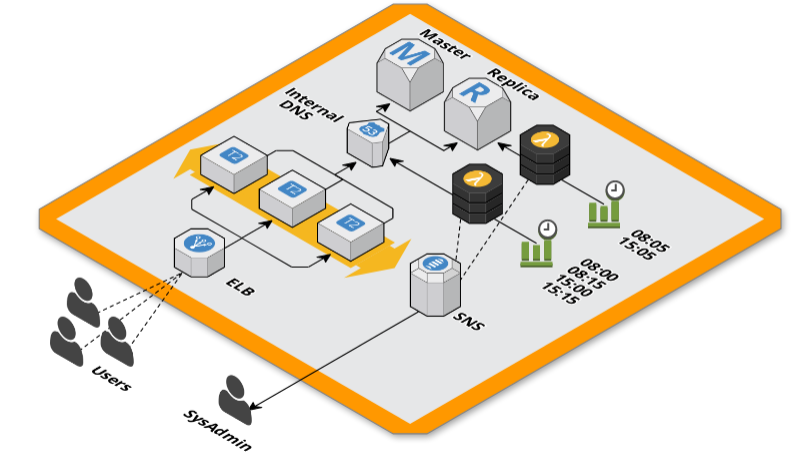
Nothing remained to scheduled the Lambda executions. After numerous runs we made an estimate of how much time each step took and decided to roll out the executions using scheduled CloudWatch events with this type of configuration:
- 08:00 GMT routing to master database
- 08:05 GMT scale up RDS instance
08:15 GMT routing to replica database
15:00 GMT routing to master database
15:05 GMT scale down RDS instance
15:15 GMT routing to replica database
This give to the DNS 5 minutes to propagate (using a 60s TTL) and 10⁄12 minutes to the RDS instance to complete the scaling, scaling time plus the propagation time of the second DNS change.
Events
We have analyzed the list of events launched by RDS and Route53 services so that we can connect to one or another and for us remain some doubts.
Changing the value of a DNS record involves waiting for its propagation and closing any existing database connections, there are no events for this, and it would not be possible to wait with a long polling until the modification is completed.
Modifying an RDS instance triggers some events during this type of modification, the first “DB instance shutdown” when the instance begins scaling, and then “DB instance restarted” at the instance restart. However, being a replica needs some extra time to finish synchronizing with the master and we are not quite convinced of an event-driven solution.
We will better analyze this solution if we go to this type of configuration. Why not use this or that We did not use a CPU usage or RDS memory alarm to trigger scaling due to the sudden increase of connections there was no time to scale and endure traffic.
Why not stop a second big replica and redirect the traffic on it after turning it on? As specified in AWS documentation, you can not stop reading a replica. If we want a larger or smaller instance, we just have to change a Lambda environment variable instead of scaling an instance in stop state.
We chose to scale instead of destroying and recreating because we use Terraform to manage the infrastructure we would have to import the new RDS instance id into the tfstate and this caused a few headaches.
Post of

☝ Ti piace quello che facciamo? Unisciti a noi!
You may be interested also in...
-

My serverless journey
|How many times have you heard of Serverless? I’ve heard about it so many, too many maybe,so I decided to embark on this journey to discover this new technology.
-

How to update our ecommerce prices using AWS SES
|Introduction The presented solution is inspired by a specific need of a customer of ours: to allow purchasing managers to update the online store’s price lists quickly without forcing them to use a new tool. -
Ingress rules for dynamic IPs
|Management of Security Group ingress rules to allow access to dynamic IPs. Necessity Our infrastructures are designed to remain isolated in a private subnet of the VPC, this in order to increase the security level and block any type of unwanted access directly from network layer.