
Scaling Automatico Temporizzato Rds
Lettura 6 minuti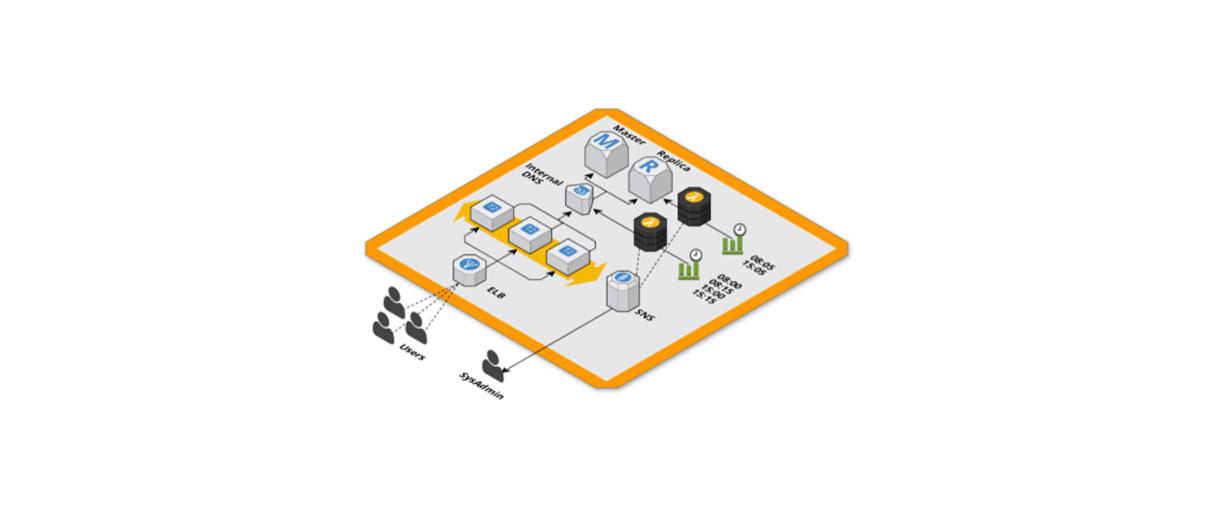
Scaling automatico e temporizzato di un database RDS Read Replica con Lambda e Route53
La situazione di partenza
Una delle nostre infrastrutture in hosting su AWS di recente ha riscontrato qualche problema dovuto ad un enorme e rapido aumento di traffico durante alcuni orari prestabiliti, in concomitanza ad una newsletter che portava velocemente molti più utenti del solito a visitare l’e-commerce Magento.
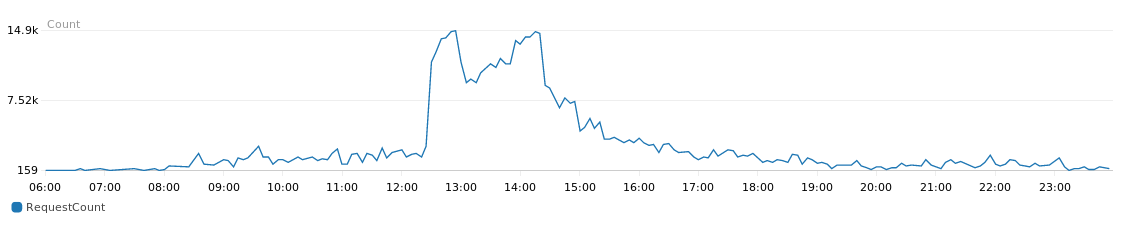
Il numero di richieste fatte al nostro ElasticLoadBalancer passava da 400 a 3000 al minuto in meno di 5 minuti, questo non ci dava il tempo di scalare sul momento l’infrastruttura prima che cadesse rovinosamente. Da una nostra analisi abbiamo individuato il collo di bottiglia nel database, in particolare nelle query di lettura delle categorie e catalogo, dinamiche in base a varie configurazioni e basate sull’utente collegato.
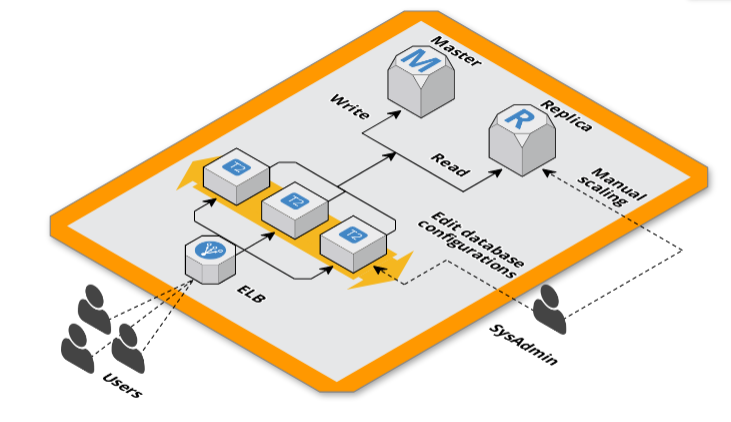
RDS master e replica
Per tenere meglio sotto controllo il carico sul database abbiamo deciso di utilizzare due istanze RDS, una master per le operazioni di scrittura e una replica per le operazioni di lettura in modo da scalare solo la parte necessaria e tenere sotto controllo i costi. Abbiamo notato un miglioramento ma lo stesso la read replica soffriva del carico e si saturavano velocemente le connessioni al database.
Scaling programmato
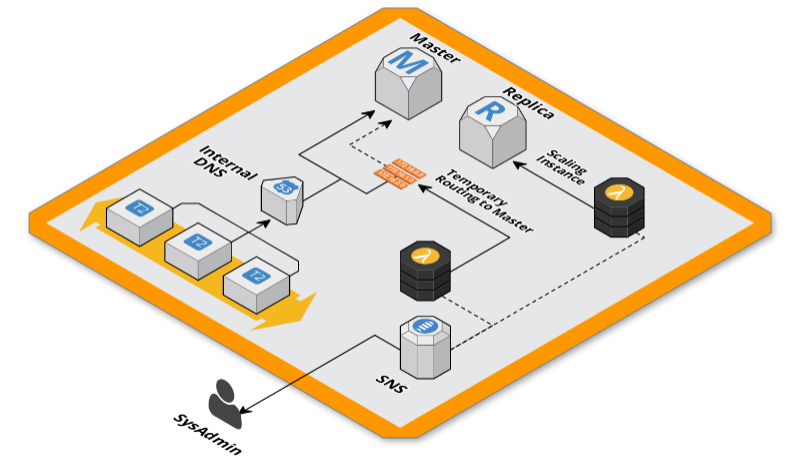
Per prepararci al traffico in arrivo, un’ora prima del picco di traffico cambiavamo il puntamento del database dalle configurazioni di Magento per non usare la replica. Finito lo scaling portavamo di nuovo la configurazione com’era in precedenza.
Questa soluzione funzionava correttamente ma era molto scomoda: per cambiare le configurazioni di Magento dovevamo svuotare la cache e questo comportava un ulteriore carico alle prime visite successive del sito in aggiunta al fatto di dover fare le procedure manualmente con il rischio dell’errore umano.
DNS interni con Route53
La soluzione che abbiamo adottato per non dover modificare le configurazioni di connessione al database di Magento è stata quella di utilizzare dei DNS interni alla VPC gestiti con Route53 mappando gli hostname delle istanze RDS con nomi di dominio, utilizzando dei record CNAME, così da inserire quest’ultimi nelle configurazioni di magento.
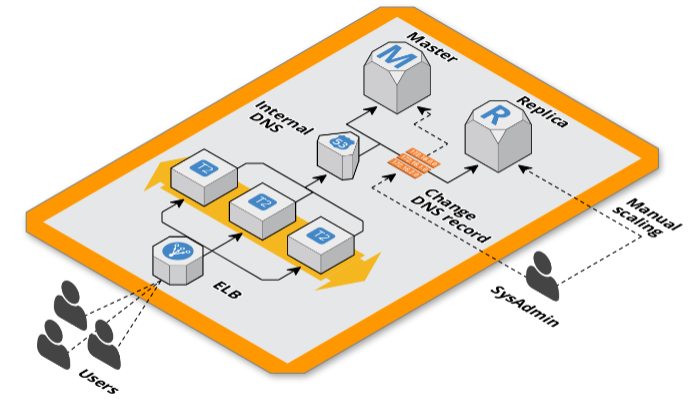
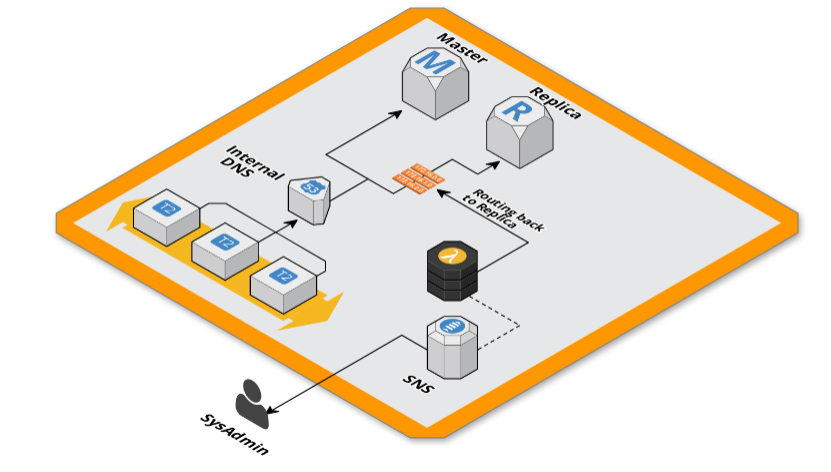
In questo modo abbiamo il controllo del puntamento dell’applicativo web al database in maniera agnostica alle sue configurazioni. Questo ci permette di redirigere le connessioni della read replica verso il master durante lo scaling per non generare downtime.
I computer ci ruberanno il lavoro
Arrivati ad una soluzione stabile che ci consenta di scalare senza momenti di down rimaneva solo da impostare questa procedura in modo automatico.
“Questo è un compito per Lambda” ci siamo detti, quindi abbiamo scritto due funzioni Lambda in NodeJS che siano in grado di modificare l’istanza RDS e il record DNS di Route53 collegato al suo endpoint. Per questo piccolo progetto abbiamo scelto di utilizzare il framework Serverless già utilizzato in passato con ottime soddisfazioni. Abbiamo usato questa configurazione:
functions:
routingToMaster:
handler: route53.changeRecord
environment:
Msg: "${self:custom.MsgRoutingToMaster}"
HostedZoneId: "${self:custom.HostedZoneId}"
RecordName: "${self:custom.RecordName}"
RecordValue: "${self:custom.MasterEndpoint}"
scaleUp:
handler: rds.scale
environment:
Msg: "${self:custom.MsgScaleUp}"
InstanceIdentifier: "${self:custom.InstanceIdentifier}"
InstanceClass: "${self:custom.InstanceClassBig}"
scaleDown:
handler: rds.scale
environment:
Msg: "${self:custom.MsgScaleDown}"
InstanceIdentifier: "${self:custom.InstanceIdentifier}"
InstanceClass: "${self:custom.InstanceClassSmall}"
routingToReplica:
handler: route53.changeRecord
environment:
Msg: "${self:custom.MsgRoutingToReplica}"
HostedZoneId: "${self:custom.HostedZoneId}"
RecordName: "${self:custom.RecordName}"
RecordValue: "${self:custom.ReplicaEndpoint}"Le due funzioni Lambda vengono chiamate con due diverse configurazioni ciascuna, riguardo il DNS prima per puntare verso il master poi per ri-puntare verso la replica
'use strict';
const AWS = require('aws-sdk');
const route53 = new AWS.Route53();
const sns = require('./lib/sns.js');
module.exports.changeRecord = (event, context, callback) => {
route53.changeResourceRecordSets({
ChangeBatch: {
Changes: [{
Action: 'UPSERT',
ResourceRecordSet: {
Name: process.env.RecordName,
Type: 'CNAME',
ResourceRecords: [{
Value: process.env.RecordValue
}],
TTL: 60
}
}],
Comment: "managed by lambda"
},
HostedZoneId: process.env.HostedZoneId
}, function(err, data){
if(err){
sns.error("Cannot change DNS record "+process.env.RecordName+" to value "+process.env.RecordValue, function(){
callback(err);
})
}else{
sns.notify(process.env.Msg, callback)
}
});
};
per RDS per uno scale-up e uno scale-down alla taglia di partenza.
'use strict';
const AWS = require('aws-sdk');
const rds = new AWS.RDS();
const sns = require('./lib/sns.js');
module.exports.scale = (event, context, callback) => {
rds.modifyDBInstance({
DBInstanceIdentifier: process.env.InstanceIdentifier,
DBInstanceClass: process.env.InstanceClass,
ApplyImmediately: true
}, function(err, data){
if(err){
sns.error("Cannot scale RDS instance "+process.env.InstanceIdentifier+" to "+process.env.InstanceClass, function(){
callback(err);
})
}else{
sns.notify(process.env.Msg, callback)
}
});
};
Abbiamo aggiunto l’invio di messaggi in un topic SNS per essere notificati quando le operazioni avvenivano e nel caso di problemi essere pronti ad intervenire.
'use strict';
const AWS = require('aws-sdk');
const sns = new AWS.SNS();
module.exports.notify = (msg, callback) => {
sns.publish({
Message: msg,
TopicArn: process.env.NotificationSNS
}, callback);
};
module.exports.error = (error, callback) => {
sns.publish({
Message: process.env.MsgError +": "+ error,
TopicArn: process.env.NotificationSNS
}, callback);
};
Una nostra funzione Lambda generica è in ascolto su un determinato topic ed è in grado di elaborare molti tipi di messaggi in arrivo inoltrandoli in una stanza specifica di Slack.
Una volta scritto il codice, minimale e semplice, e configurato il progetto Serverless è bastato eseguire un comando di deploy per avere tutto l’ambiente up&running.
Potete trovare tutto il codice qui: bitbull-team/aws-rds-autoscaling
Scaling programmato ed automatico
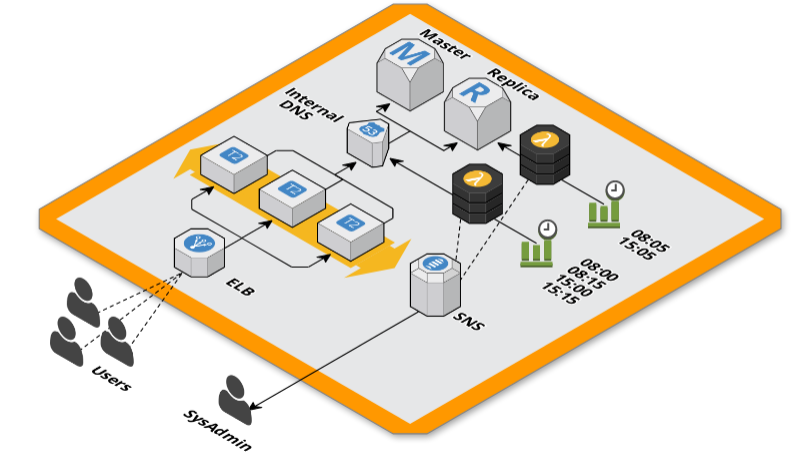
Non rimaneva che impostare gli orari delle esecuzioni delle Lambda. Dopo numerose esecuzione abbiamo fatto una stima di quanto tempo impiegava ogni step e deciso di cadenzare le esecuzioni utilizzando degli eventi CloudWatch schedulati con questo tipo di configurazione:
- 08:00 GMT routing verso database master
- 08:05 GMT scale up istanza RDS
08:15 GMT routing verso database replica
15:00 GMT routing verso database master
15:05 GMT scale down istanza RDS
15:15 GMT routing verso database replica
Questo dà al DNS 5 minuti per propagarsi (utilizzando un TTL di 60s) e concede all’istanza RDS 10⁄12 minuti per completare lo scaling, tempo dello scaling più parte del tempo di propagazione della seconda modifica al DNS.
Eventi
Abbiamo analizzato l’elenco degli eventi lanciati dai servizi RDS e Route53 per poterci collegare ad uno oppure ad un altro e ci sono venuti alcuni dubbi.
Cambiare il valore di un record del DNS comporta l’attesa della sua propagazione e la chiusura di eventuali connessioni già attive, non ci sono eventi al riguardo e non sarebbe possibile attendere con un long polling che la modifica sia terminata.
La modifica di un’istanza RDS scatena alcuni eventi durante questo tipo di modifica, il primo “DB instance shutdown” quando l’istanza comincia lo scaling, successivamente “DB instance restarted” al riavvio dell’istanza. Essendo però una replica ha bisogno di un po’ di tempo aggiuntivo per terminare la sincronizzazione con il master e non ci ha del tutto convinto una soluzione event-driven..
Ci riserviamo di analizzare meglio questa soluzione nel caso passeremo a questo tipo di configurazione.
Perché non utilizzare questo o quello Non abbiamo collegato un allarme di utilizzo di CPU o memoria dei RDS per scatenare lo scaling visto l’aumento repentino di connessioni non c’era il tempo per scalare e sopportare il traffico.
Perché non tenere in stop una seconda replica molto grossa e dirottare il traffico su di essa dopo averla accesa? Come specificato nella documentazione di AWS non è possibile mettere in stato di stop una read replica. Nel caso volessimo una istanza più grossa o più piccola ci basta cambiare una variabile d’ambiente della Lambda invece di scalare un’istanza in stato di stop.
Abbiamo scelto di scalare invece di distruggere e ricreare visto che utilizzando Terraform per gestire l’infrastruttura avremmo dovuto importare il nuovo identificativo dell’istanza continuamente nel tfstate e questo causava non pochi grattacapi.
Articolo scritto da

☝ Ti piace quello che facciamo? Unisciti a noi!
Ti potrebbe interessare anche..
-

Il mio viaggio nel mondo serverless
|Quante volte avete sentito parlare di Serverless? Io davvero tante, troppe forse, quindi ho deciso di intraprendere questo viaggio alla scoperta di questa nuova tecnologia.
-

Come aggiornare il listino del proprio ecommerce via email sfruttando AWS SES
|Introduzione La soluzione che vi presentiamo nasce da un’esigenza specifica di un nostro cliente: consentire ai responsabili acquisti di aggiornare i listini del negozio online in modo facile, senza obbligarli ad utilizzare un nuovo strumento. -
Regole di ingresso per IP dinamici
|Gestione delle regole di ingress dei Security Group per consentire l’accesso ad IP dinamici.