
Cos'è il Machine Learning e il suo ruolo nell'e-commerce
Lettura 7 minuti
Il Machine Learning è una branca dell’intelligenza artificiale il cui obiettivo è realizzare macchine che apprendono o migliorano le performance sulla base dei dati che utilizzano, è un meccanismo simile a quello usato dalla mente umana.
Sebbene io non sia un esperto di machine learning, resto comunque affascinato dalle possibilità che questa tecnologia offre oggi, quindi ho deciso di rimboccarmi le maniche e iniziare a capire cosa c’è dietro un argomento che è sulla bocca di tutti !
Alla base del ML ho trovato un concetto semplice: il comportamento degli algoritmi non è più programmato, ma è determinato dall’apprendimento dei dati (che tra Data Science, Data Mining e Big Data, ormai non mancano mai!).
Prima del ML
In passato, se si voleva “addestrare” una macchina a riconoscere cose o situazioni, era necessario prevedere in anticipo tutti i possibili scenari. Si realizzavano i cosiddetti Rule Based Systems, i quali non sono altro che una collezione di if then per elencare le tantissime possibilità. Proprio in questo modo è nato a Stanford il MYCIN, un sistema in grado d’identificare i batteri che causano infezioni e suggerire gli appositi antibiotici 
Un approccio del genere comporta migliaia di linee di codice da scrivere (e mantenere aggiornate!)
Oggi, con il ML
L’idea è quella di utilizzare algoritmi generici che possano estrarre informazioni utili da un calderone di dati, senza dover formalizzare tutti gli aspetti del problema da dover analizzare. Di fatto, un sistema di ML, cerca di scoprire quali sono i patterns che si celano nei dati e li sfrutta per le analisi sugli input futuri. Non si tratta di una tecnica precisa, ma di diversi algoritmi che usano differenti approcci per analizzare l’ingresso e ricavare informazioni sull’uscita del sistema. Non sono entrato subito nel dettaglio di come funzionano i singoli algoritmi, ma ho capito che una prima distinzione che si individua tra questi è basata sul tipo di apprendimento.
Apprendimento supervisionato
In una prima fase, detta di addestramento, vengono forniti in input al sistema coppie di valori: il dato e una label (che coincide con il risultato atteso). Sarà il sistema a dover trovare una regola che metta in relazione le due informazioni, in modo tale che, a seguito del training e a fronte di input sconosciuti, si riescano ad ottenere risultati corretti. Questo tipo di apprendimento è utilizzato tipicamente per i problemi di classificazione.
Ecco un piccolo esempio:
Consideriamo il cagnetto Bitbullo, la nostra mascotte a cui piace moltissimo ascoltare la musica.
Ipotizziamo di voler individuare le possibili canzoni che gradirebbe avere nella sua playlist.
I parametri di una canzone che potremmo analizzare sono diversi, limitiamoci a raccogliere informazioni relative al tempo e all’intensità della musica.
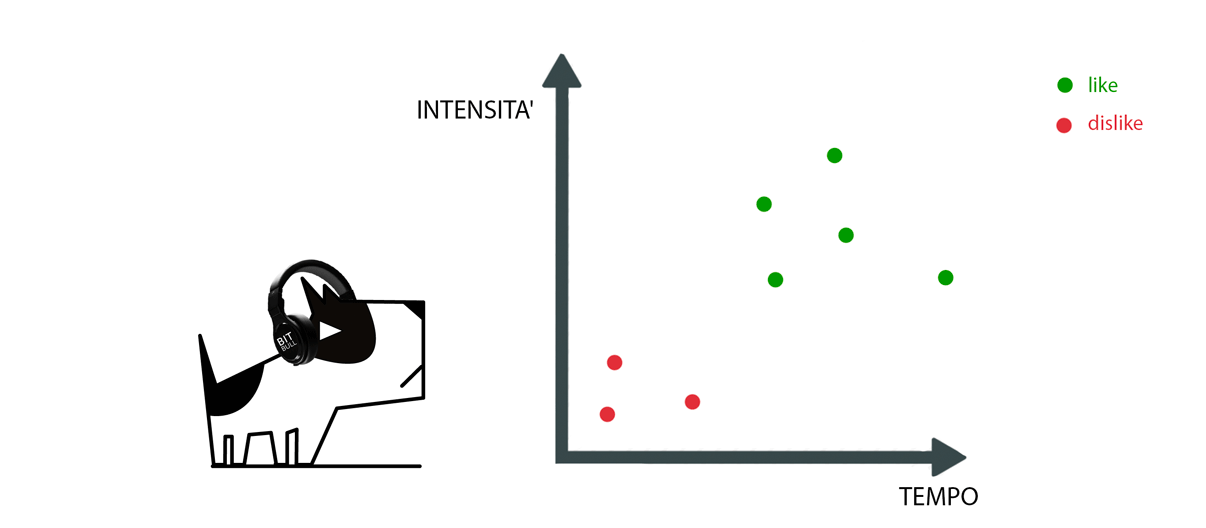
Durante la fase di training i dati che forniamo al sistema sono i valori dei parametri che abbiamo scelto, insieme ai like e dislike (le labels) che Bitbullo ha cliccato mentre ascoltava la musica. Dal grafico è evidente che al cagnetto piace la musica con valori più alti in intensità e tempo (infatti è un tipo da disco!). Se volessimo predire quali canzoni gradirebbe nella sua playlist ci basterebbe selezionare le canzoni aventi i valori di tempo e intensità collocate nella parte alta e a destra del grafico.
Apprendimento NON supervisionato
In questo caso non forniamo al sistema una classificazione iniziale dei dati, il suo compito sarà proprio di estrarre una regola che raggruppi i dati in input secondo caratteristiche che ricava dai dati stessi. Per la sua natura è quindi molto utilizzato per risolvere problemi di clustering, nei quali si vuole tirar fuori dai dati informazioni non ancora note.
In ambito e-commerce potrebbe tornare utile, ad esempio, per individuare segmenti di vendite basate su prezzo per unità e quantità, potremmo scoprire che tra i prodotti che abbiamo venduto esiste una correlazione tra questi due valori. Potremmo anche evidenziare gruppi di utenti simili tra loro in modo da poter impostare campagne di marketing basate su acquisti passati dei gruppi individuati.
A volerla dire tutta esiste un terzo tipo di classificazione, l’apprendimento con rinforzo, dove i dati passati in input al sistema vengono processati e si fornisce un feedback al sistema, sulla base del risultato atteso.
Quindi? A che può servirmi questa roba?
In effetti, oggi il ML è impiegato per coprire diverse funzionalità presenti su uno store online, tra gli spunti interessanti sicuramente sono da prendere in considerazione:
Ottimizzazione del prezzo
il prezzo ottimale è il risultato di un trade off tra:
Obiettivi dell’azienda
Prezzi dei competitors
Stagionalità
Richiesta locale
Quantità di prodotti venduti
Costi operativi
Demandare quest’onere al ML, oltre che snellire il carico di lavoro, permette di arrivare ad avere un risultato più preciso.
Previsione della domanda
Avere a disposizione un numero insufficiente di items di un certo prodotto potrebbe significare che presto vada out of stock, d’altronde averne più del necessario implicherebbe costi del magazzino superflui. Permettere all’intelligenza artificiale di apprendere cosa (e in che momento) comprano gli utenti potrebbe risolvere in maniera efficace questo problema.
Ricerca
Quando i clienti iniziano una ricerca sul sito è molto probabile che si trovino in una fase avanzata del ciclo di acquisto, garantire che le loro ricerche portino ai risultati pertinenti è fondamentale per fornire un’ottima esperienza e una probabile vendita.
Il ML è uno strumento molto potente per questo aspetto. Il matching esatto non è il solo obiettivo, i prodotti devono essere trovati aldilà dell’errore ortografico. Zalando fa un uso importante della teecnologia che stiamo trattando, provate a cercare “scarpe addidass” sul suo sito e poi su solarissport.com oppure su cisalfasport.it (non me ne vogliano i rispettivi store managers!), i risultati saranno ben diversi nonostante le scarpe adidas siano presenti sui loro cataloghi.
Classificazione dei prodotti: Assegnare la giusta categoria può essere faticoso per cataloghi molto vasti. Gli errori possono essere costosi, dal momento che i prodotti non categorizzati correttamente, appaiono confusi e potrebbero non essere trovati dai customers che cercano nelle categorie giuste. Molte soluzioni che vedono l’impiego del ML riescono ad automatizzare questo processo sfruttando i testi afferenti al prodotto (come titolo o descrizione), oppure utilizzando le immagini.
Gestione delle risorse del server: oltre agli aspetti di business e di applicazione, il ML può tornare utile per la gestione dell’infrastruttura che ospita lo store. Ad esempio AWS mette a disposizione lo scaling predittivo, che, sulla base dei dati storici dell’istanza, riesce a fornire previsioni sul carico atteso nei successivi giorni o settimane, ridimensionando adeguatamente le risorse, evitando costi superflui e riducendo significativamente il tempo in cui il sito potrebbe essere non disponibile.
Sistemi di alert: monitorando nel tempo il comportamento di un ambiente è possibile stabilire quali siano i margini di normalità entro il quale esso opera. Il superamento di tali soglie potrebbe essere sfruttato per generare alerts. Possiamo pensare ad un sistema di alerts basato sul flusso di vendite (che ovviamente tiene conto di stagionalità, localizzazione e altri fattori) per stabilire se in un certo istante potrebbe esserci o meno un malfunzionamento, il trigger dovrebbe scattare se il flusso di vendite non rispecchia le previsioni fatte dall’IA.
Sistemi di raccomandazione sono un po’ come i commessi di un negozio, tu chiedi informazioni per un prodotto e loro ti mostrano il prodotto insieme ad una serie di altri articoli che potrebbero interessarti, come se tu fossi un vecchio cliente, oppure ti mettono sul banco i prodotti sui quali hanno più margine di guadagno.
Per una rapida lettura su Upselling e Cross-Selling ho trovato un interessante articolo su Forbes , dove, tra l’altro, viene riportato che Amazon attribuisce più del 35% dei suoi ricavi alle tecniche di Cross-selling.
Rimanendo in tema Amazon e recommendation systems, su AWS è disponibile il servizio Amazon Personalize, che sfrutta gli stessi algoritmi utilizzati dal sitarello di Jeff Bezos per permetterti di costruire il tuo sistema di raccomandazione. Se non sai da dove partire, prova a seguire il loro tutorial per creare il tuo Netflix fatto in casa (d’altronde abbiamo già visto come si fa Spotify! 😅).
In conclusione, tornando al nocciolo della questione, ci sono moltissime spiegazioni tecniche che potrebbero essere fatte sull’argomento, ma prima di tutto è necessario aver chiaro che i dati sono un tassello fondamentale per questa tecnologia, bisogna averne una buona quantità e soprattutto è importante sapere come utilizzarli. Diversamente sarebbe difficile sfruttare al meglio il Machine Learning per raggiungere gli obiettivi di ogni store manager, ossia portare il business legato all’e-commerce a un livello sempre più interessante.
Articolo scritto da
Gennaro Oliviero☝ Ti piace quello che facciamo? Unisciti a noi!